GANと著作権:製造現場の視点で解く「類似性」と「依拠性」
GANの仕組みと著作権の3大論点
「偽造者vs警察官」の闘いから生まれる法的リスク
1. GANのメカニズム:プロフェッショナルな比喩 (Generative Adversarial Networks=GAN)
【GAN:究極の『騙し合い』が生む進化】
GAN(敵対的生成ネットワーク)は、2つのAIを**「ゼロサム・ゲーム」**の状態で戦わせる仕組みです。
- 生成器(Generator): 偽造者(クリエイター)。「偽造データ」を作り、検査員を騙すことがミッション。
- 識別器(Discriminator): 警察官(インスペクター)。本物のデータと偽物を見分け、偽物を見破ることがミッション。
偽造者が**勾配(Gradient)を頼りに、より本物に近い「特徴量」を生成し、警察官がそれをさらに厳しく検閲する。
この「敵対的な学習プロセス」**を数万回繰り返すことで、最終的に人間にも見分けがつかないレベルのデータが誕生します。著作権の議論になるのは、この「偽造者」が、本物の絵(誰かの著作物)を**『教科書』として徹底的にコピー学習する**という仕組みそのものが、内包されているからです。
ところで、GAN以前のAIは「猫か犬か」を当てる「識別」が専門でしたが、GANは「人間顔負けのクリエイティブ(生成)」に足を踏み入れました。これが法整備を追い越してしまった理由です。
2. GANによる活動と知財リスク(比較表)
項目 | GANによる活動 | 著作権・知財上のリスク |
|---|---|---|
リバースエンジニアリング | 競合製品から設計思想を再構成 | 不正競争防止法・意匠権侵害リスク |
デザイン生成 | 過去のヒット作を学習し新外観を出す | 過去製品との「類似性」および「依拠性」が問われる |
偽造防止 | 偽物を見破る識別器を訓練 | 防御側の技術(攻守両方なのが厄介) |
💡 補足:著作権法第30条の4(豆知識) 「AI学習のためにデータを使う(依拠)こと」自体は日本法では原則自由です。ただし、出力されたものが「似ている(類似)」場合は、従来通り著作権侵害を問われる可能性があります。
類似性(Similarity)
「結果(アウトプット)」のチェック。 製造現場の例:A社とB社の製品を並べたとき、見た目や機能の配置がそっくりな状態。あくまで「表現」が似ているかどうかだけを見ます。
依拠性(Reliance)
「プロセス(過程)」のチェック。 製造現場の例:B社の設計者が、A社の設計図を「見て」作ったという因果関係。全く知らずに偶然同じものを作ったなら、依拠性がないため侵害になりません。
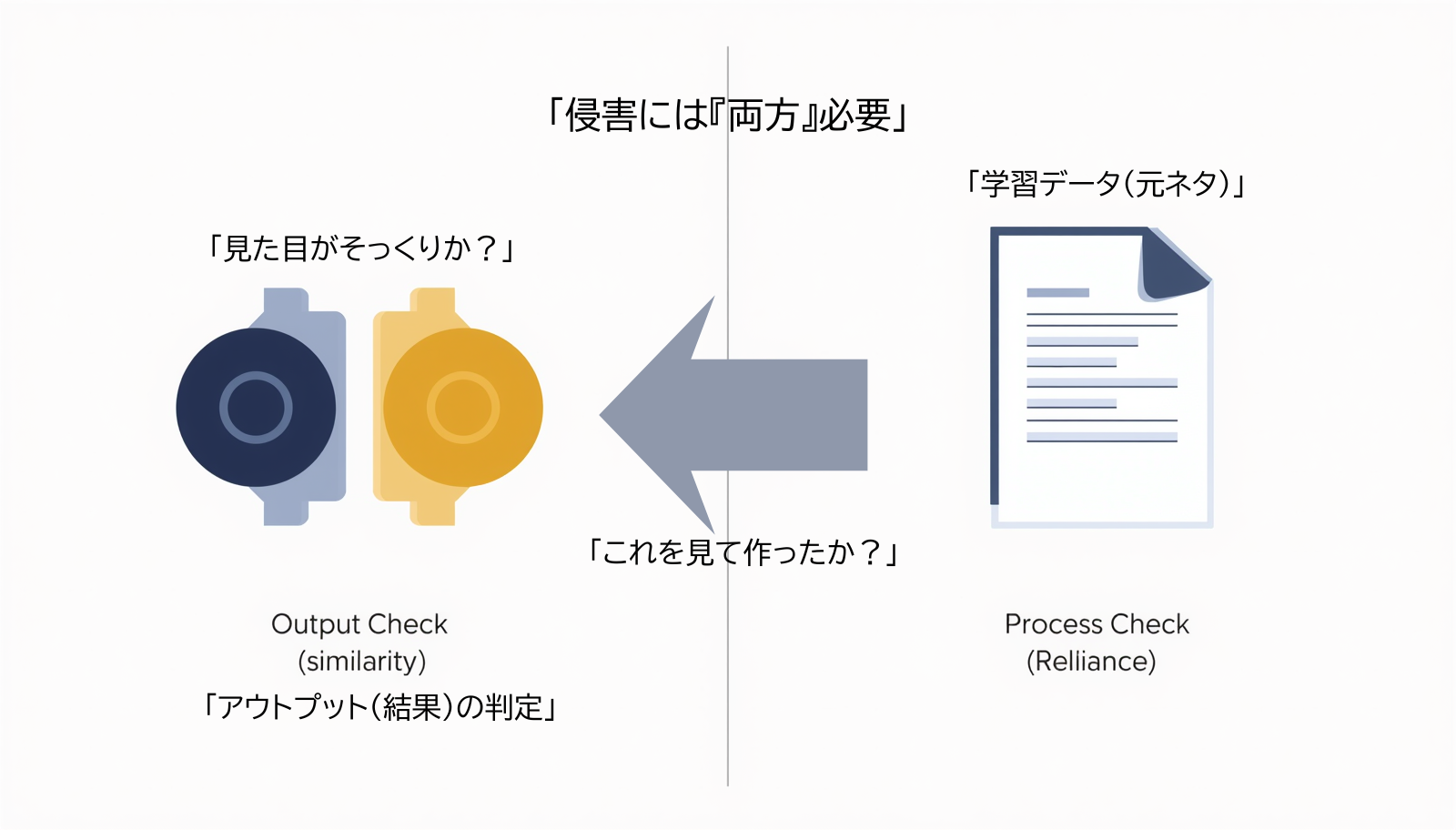
著作権侵害の成立に不可欠な「見た目のそっくりさ(類似性)」と「元ネタの使用(依拠性)」という2大条件の相関関係を可視化した構造図です。
3.【解説】類似性と依拠性:著作権侵害の「二大条件」
著作権侵害を判定する際、裁判所はこの図にある2つのハードルをチェックします。これは、製造現場における「特許侵害」の考え方にも非常に近いです。
- 類似性(左側):アウトプットのチェック 鏡合わせのパーツのように、出来上がったものが既存の著作物と「表現上の本質的な特徴」を共有しているかを判定します。自動車部品で言えば、「見た目の形状やネジ穴の配置が瓜二つ」という状態です。
- 依拠性(右側):プロセスのチェック 右側の図にある矢印のように、作者(AI)が元ネタ(設計図)に「接触」して、それを元に作ったかという因果関係を判定します。
💡 ここがポイント! AIの世界では、たとえ左側の「類似性(激似)」があったとしても、AIがそのデータを全く学習していなかった(中央の矢印が存在しない)場合、「依拠性なし」となり、著作権侵害にはなりません。これを「偶然の一致」と呼びます。
※ただし、依拠性の有無について、AIの世界では、判断が困難なことも事実であります。上記『偶然の一致』となったとしても、元の作品に対して害を及ぼす行為になれば、著作権侵害と判断される可能性が高いといえます。また学習過程において元の作品のコピーなどを用いたという事実が発覚すれば、それは、依拠したとみなされる可能性が高い。やはり、類似性がめちゃくちゃあるものは、その利用用途を慎重に判断した方が良いですね。
4. 類似性と依拠性の違い(まとめ表)
項目 | 類似性 (Similarity) | 依拠性 (Reliance) |
|---|---|---|
対象 | 作品そのもの(結果) | 作成者の行動(過程) |
問い | 「見た目が似ているか?」 | 「元の作品を知ってたか?」 |
AIでの意味 | 生成画像が既存の絵に似ている | その絵が学習データに入っていた(特定・断定が困難) |
まとめSummary
GANと著作権を巡る「3大論点」の整理
今回の内容を、G検定での頻出ポイントの重要課題でもある「3つのフェーズ」で総括します。
① 【学習段階】材料の調達(著作権法30条の4)
- 内容: AIに学習させるために、他人の著作物を「勝手に読み込む」ことの是非。
- 結論:原則として自由。
- 製造現場の視点: 「新製品開発のために、世の中にある全ての競合製品をバラバラに分解して(リバースエンジニアリングして)研究する」行為は、原則として許されるのと同じ理屈です。
② 【生成段階】アウトプットの評価(類似性と依拠性)
- 内容: AIが作り出したものが、既存の作品と似すぎている場合のリスク。
- 結論:侵害には「類似性」と「依拠性」の両方が必要。
- 製造現場の視点:
- 類似性: 出来上がった製品(アウトプット)が瓜二つか?
- 依拠性: 開発プロセスで相手の設計図(学習データ)を盗み見ていたか?
- どちらか一方が欠けても(=たまたま似てしまった、など)侵害にはなりません。
- ただし、類似性が非常に高い生成物により、既存作品への活動侵害が認められれば、著作権侵害となりうる。
③ 【権利の所在】オーナーシップの行方
- 内容: AIが生み出した「創作物」の権利は誰が持つのか?
- 結論:AI単体には「著作権」は発生しない。
- 製造現場の視点: 工場のロボットが勝手に作り出したガラクタに「独占権(特許)」が認められないのと同様です。
ただし、「人間がAIを道具として使い、創作的寄与をした」と認められる場合のみ、その人間に権利が発生します。
AIがある画家の絵を学習していない(依拠性なし)状態で、偶然そっくりな絵を出力した(類似性あり)場合、著作権侵害になりますか?
▶解答を見る
正解:ならない。 解説:著作権侵害には「類似性」と「依拠性」の両方が必要です。どんなに似ていても、プロセス(依拠)がなければ、製造現場における「偶然の一致」と同じ扱いになります。
※ただし、ある画家の既存作品への活動侵害が認められれば、著作権侵害となる確率は高いです。
類似性があると判断できる場合、私的使用の範囲を超えない方が良いですね!